Performance isn't just for FORTRAN
This post was written more than 2 years ago, just so you know.
Table of Contents
Performance in software can be a very contentious thing. On the one hand, you have people who say that allocating even one string on the heap is too slow and why don't you just handcraft your own assembly instructions come on. On the other hand, you have people say that performance is a non issue these days because computers got so fast that almost anything you do is "fast enough". Finally, there are the corporate bozos that keep reminding us that the future of cloud computing is here, and with the click of a credit card you can have a box 10 times as large, so stop worrying will you. I'm here to tell each of these people that they are incorrect. That's right, all of them.
The problem is that it seems to be that people can only ever exist at the ends of this spectrum and that annoys me. So I'm about to argue against both positions. It might appear as if my opinions are contradictory, and maybe they are, but hey, I am human; I contain multitudes. Not just that, but I'm not just trying to convince you of something specific in this article, but open up a conversation. If anything, what I want to do in this article is convince you that performance is worth thinking about, whatever conclusions you'll end up with. With all of that out of the way, let's get started!
Just write better code, brah
There will always be people who say that "it's not that hard, just write better code". While this is pretty much always a disingenuous statement made without thinking of the people on the other side, it is especially false with performance. Before we get into my dissertation proper, I want to lie out a few examples of why performance can be so hard. The major reason is that we already get so much of those improvements "for free". To improve what is there, you need to at least nominally understand what is already there.
If you want things to become faster, there are two things you can do: make the work go faster, or figure out a way to do less work. Let me show what I mean with a few examples. Consider why the following two snippets are equivalent (given there is only one answer), but the latter is faster:
int guess_password1(int hashed_password) {
int ans;
for (int i = 0; i < 1e6; i++) {
if (hash(i) == hashed_password) {
ans = i;
}
}
return ans;
}
int guess_password2(int hashed_password) {
int ans;
for (int i = 0; i < 1e6; i++) {
if (hash(i) == hashed_password) {
return i;
}
}
}The second answer stops searching once it finds the answer, while the first one continues searching until it has tried all possibilities before giving the answer. It's literally doing less work.
Now here's a more tricky one. Which of these two functions do you think will be faster than the other, if any (given the if conditions are true in the same number of cases)?
int foo(int * array) {
int sum = 0;
for (int i = 0; i < ARRAY_SIZE; i++) {
if (rand() % 2 == 0) {
sum += array[i];
}
}
return sum;
}
int bar(int * array) {
int sum = 0;
for (int i = 0; i < ARRAY_SIZE; i++) {
if (array[i] >= 0) {
sum += array[i];
}
}
return sum;
}
If you're like me, you'd expect these functions to be about the same, right? Yeah, about that...
❯ hyperfine ./foo ./bar -w 20 -r 500
Benchmark 1: ./foo
Time (mean ± σ): 35.7 ms ± 15.0 ms [User: 30.7 ms, System: 5.0 ms]
Range (min … max): 22.6 ms … 68.5 ms 500 runs
Benchmark 2: ./bar
Time (mean ± σ): 18.1 ms ± 5.7 ms [User: 10.4 ms, System: 7.6 ms]
Range (min … max): 7.0 ms … 23.9 ms 500 runs
Summary
./bar ran
1.97 ± 1.03 times faster than ./fooOne of them is literally twice as fast as the other. Your mileage may vary if you run the benchmarks yourself, depending on your computer etc. but I think it's fairly clear that there is a difference. Do you know why? It's because of branch prediction. This is an optimisation that happens at the CPU level. I won't go into detail about it here, but if you're curious the wikipedia article provides an excellent overview. The point I'm trying to make is how incredibly subtle the difference can be, and how much you need to know about for spotting them.
Another optimisation that people might not know about is that compilers have a lot more leeway with your code than you think. They are allowed to ignore or reorder bits of your code as long as they believe it won't make a difference. (fun fact, did you know that reordering code by the system was invented by a trans woman?). For example, consider the following two simple C functions:
int foo() {
if (4 > 5) {
return 1;
} else {
return 0;
}
}
int bar() {
return 8 + 3;
}If you run gcc with the -S command, it will also output the assembly it created alongside the program. I know assembly can be intimidating, but bear with me. Here are the (slightly cleaned up) resulting instructions:
foo:
pushq %rbp
movq %rsp, %rbp
movl $0, %eax
popq %rbp
ret
bar:
pushq %rbp
movq %rsp, %rbp
movl $11, %eax
popq %rbp
retI'll spare you a detailed explanation of how assembly works, but the bits that you should pay attention to are movl $0, %eax and movl $11, %eax. These are basically assembly speak for return 0 and return 11 respectively. All the arithmetic and logic are gone, because the compiler figured out the answers will always be the same. This was a really simple example, but there are countless others like it. If you're interested in what the C compiler is allowed to do and how that can go awry I suggest this excellent paper by Russ Cox on the subject.
Especially in performance, we already get a lot more "for free" than we realise. This means that when you want to optimise things, you need to know what's going on under the hood. If you don't, you might try to optimise something that the compiler will just throw out anyway. And these are just the bits I know about. Surely, there are countless others!
it's a trap
Because performance is so hard to understand, it's incredibly rare that significant and easy gains are just lying around. If they were, you'd probably have already done it. There is even a proverb about this: "there is no such thing as a free lunch". It's a way of saying that you can almost never get something that is simply better in every way. You're always gonna end up paying in one way or another.
This can lead to a kind of learned helplessness. So many times when I advocate for working on performance, the conversation goes something like "eh, it's not great but it's workable for now, we got other stuff to do". or "well, users will just have to wait a little bit when using our system". That is fine until it isn't anymore. This is how you get to dangerous situations. Such as your system is "fine" as long as you are developing it, but as soon as two people try to use it simultaneously, it brings down your entire production system (true story).
When something like that happens, you're stuck. You're now saddled with a system that's not fit for purpose, and, as we concluded earlier, there is no easy way out. As much as people like to bemoan premature optimisation, if you wait for a really hard problem to become a blocker, you're too late. Especially because performance is so complicated, I think you should invest in it in small increments over time. Again, I'm not advocating for trying to handcraft assembly to save every cycle we can. But even thinking about performance before it becomes unmanageable is likely to get labelled as a premature optimisation. That frustrates me hugely.
The problem with what I'm advocating for is that it's a long-term strategy. It's the exercise way to health care. It takes a long time to see the benefits. You don't see how many problems you avoided because of proper exercise and nutrition, so it's easy for people to go "eh, well whatever, that doesn't really do anything". But it does, just not immediately. Especially because performance is so complicated, it is imperative that you work on it in small increments.
The joys of performance
One other bit that is also worth discussing is that I often see performance brought up in one and exactly one place: how long does the user have to wait? While I think this is important, I think this misses the boat regarding several things.
Performance isn't just about users waiting, it's also about computing power. And computing power means both money and emissions. Have you ever thought about how much energy it takes to run a program? In their open source blog on Cloud Sustainability AWS they talk about the fact that data centres currently consume roughly 1% of all energy globally or approximately 200 terawatt hours per year. However, interestingly, what they find is that despite the cloud growing a lot in the past ten years, energy usage has stayed almost the same. You can see it on this IEA graph:
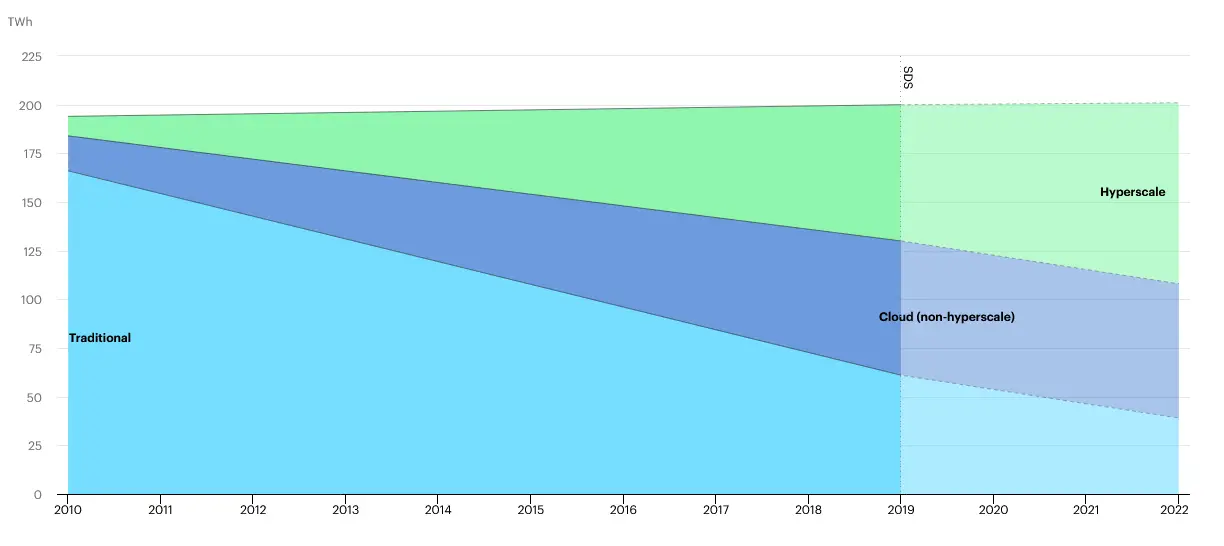
This must have been, at least in part, because of the performance gains we've made. Whether you're concerned about saving money or reducing emissions, it's hard to overlook this phenomenon. They also cite an excellent study by Pereira et al. about the energy usage of various programming languages. The authors of that paper produce the following tables:
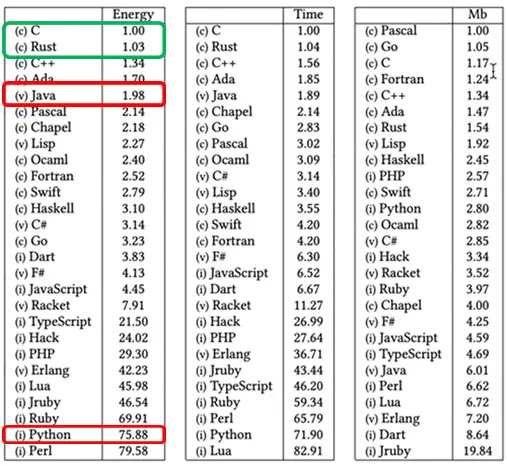
So using python requires more than 75x the amount of energy for the same task! That's insane! Now to be fair much of serious Python is actually just C in a trench coat and the study seems to have used a native python solution, so the gains might not be that dramatic in a real scenario, but even so, that's a heck of a chunk! You could decommission half your servers with that performance gain. I know this whole blog post is dedicated to arguing that performance isn't just about rewriting in a faster language, so it might seem weird to bring this up. However, I'm not arguing for a rewrite. I'm just using rewriting as a metaphor for optimisation to show you what is possible.
There is one more aspect to it I have never seen being brought up before: developer joy. I know Developer experience has become a bit of a meaningless buzzword these days, but I still think that this is worth thinking about. Speed is a feature for your developers as well. Every second that developers don't need to sit there waiting for the CIs to finish is something they could be doing something more productive. It's another opportunity for them to get distracted or invited to another meeting. I'm speaking from personal experience on that last point.
I think having performant software and workflows also improves employee satisfaction. Though I don't have hard data to back it up, check out this admittedly [very informal survey]. 77% of respondents would much rather use something fast than something they can contribute to. As Craig Mod puts it in his excellent blog point Fast Software, the Best Software:
Software that's speedy usually means it's focused. Like a good tool, it often means that it's simple, but that's not necessarily true. Speed in software is probably the most valuable, least valued asset. To me, speedy software is the difference between an application smoothly integrating into your life, and one called upon with great reluctance. Fastness in software is like great margins in a book — makes you smile without necessarily knowing why.
— Craig Mod
I find this to be equally true for users as for developers. As a developer, you're running tests, debugging, performing maintenance and deploying all day long. Introducing even minor delays here can really suck the joy out of work. Perhaps I am alone in this, but I find few things as frustrating as having to sit there for a slow CI to finish when I just want to finish one tiny thing.
Working in Rust and Go has really reinforced this for me. Using the go compiler, formatter, and LSP is a joy. They are so fast that sometimes you make intentional mistakes to just verify they are still working. And this encourages writing better code, because the faster you can get feedback, the easier it is to improve on it. If you prefer something closer to home, the Ruff linter for python is like this, too.
It is a joy that I really miss when I don't have it anymore. Working with a really fast application is a rush. It feels so good. It almost makes you feel like some kind of powerful wizard. I want more people to feel that feeling. We all deserve this, even if they don't want to rewrite our entire application in Fortran (which is where the title of this piece comes from).
Okay Sam, but what do?
Let me try to at least offer some alternative way out of this that I consider being a good middle ground. Because I've been kind of harsh on both sides of this debate. I don't want to seem like neither of these sides has their merits. Sometimes, premature optimisation is a real problem. I know I have been particularly guilty of this over the years (Steve, if you're reading this, stop laughing). Sometimes we have our darlings and we just can't help but overcomplicate things, but that doesn't mean that these issues aren't worth discussing.
On the other hand, sometimes we really need to think of performance, and not just hide behind the fact that we are using python. There is a middle ground here. I know I spent a significant part of this blog post explaining why performance minded programming is hard, but it's not impossible. There are a lot of easy first steps when it comes to performance. So here are my recommendations:
You should always be measuring. Even if you do nothing with it, just like I believe every piece of software should have a test suite, every piece of software should have some basic bench marks. Sure, you're very unlikely to get to a perfect solution, but something is better than nothing, and there are certain simple things to get you started. It is the same as testing, and we all do that, right? (RIGHT?) Even if you have to run the benchmarks manually, that is fine. I will admit here this is a place where I fall short. Performance is an area where I am trying to improve, and one aspect of that is going to be writing more bench marks for the software I write.
Learn the basics. What the basics mean will be up to you. I don't know enough about performance yet to develop an informed curriculum. In fact, I'm still busy with this step myself. But I think it makes sense for more people to at least learn the basics of how we talk about performance, you know, the real simple stuff. Performance is hard, but it's also not as mythologic as some people make it sound, and I think you'd be surprised how much you can pick up in an afternoon if you try. I'm hoping to do an "intro to performance" post here sometime, but no promises on when that will happen.
Start small and keep at it. Even if your optimisations don't produce noticeable improvements, still make them. First, because it will give you the practice and experience you need to do the big optimisations. Second, those minor changes will accumulate over time. You don't have to obsess over this, but try to keep it in mind and learn what you can.
And that's pretty much ya lot. I hope I've convinced you that the performance is at least somewhat worth thinking about. Stay safe, and stay fast, my friends!
Enjoyed this post? Help keep it ad‑free for everyone.
This site is self‑hosted, which means it stays completely ad‑ and tracker‑free and remains accessible to everyone. If you’d like to help keep it running, you can donate, or commission me via my Ko‑Fi page. I also publish a free monthly newsletter with the things I read and write. Even a one‑time contribution makes a huge difference.
![]()